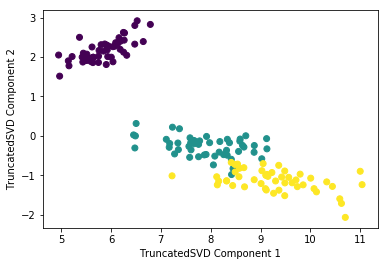
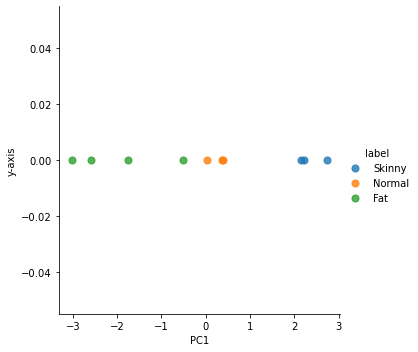
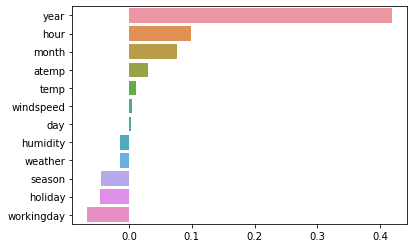
### 군집평가 - 실루엣 분석 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다. 개별 데이터가 가지는 군집화 지표인 실루엣 계수를 기반으로 한다. 개별 데티어가 자니는 실루엣 계수는 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화돼 있고, 다른 군집에 있는 데이터와는 얼마나 멀리 분리돼 있는지를 나타낸다 실루엣 계수는 -1에서 1사이의 갑을 가지며, 1로 가까워질수록 근처의 군집과 더 멀리 떨어져 있다는 것이고 0에 가까울수록 근처의 군집과 가까워진다는 것이다. 실루엣 계수가 -값이라는 것은 해당 데이터의 군집화가 잘못 되었다는 뜻이다.