RNN 순환신경망
- 순환 신경망은 여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억해 놓는 방법이다.
- 기억된 데이터가 얼마나 중요한지를 판단하여 별도의 가중치를 줘서 다음 데이터로 넘어간다.
- 모든 입력 값에 이 작업을 순서대로 실행하므로 다음 층으로 넘어가기 전에 같은 층을 맴도는 것처럼 보인다. → 이렇게 같은 층 안에서 맴도는 성질 때문에 순환 신경망이라고 부른다.
- RNN의 특성상 일반 신경망 보다 기울기 소실 문제가 더 많이 발생하고 이를 해결하기 어렵다는 단점을 보완한 LSTM(Long Short Term Memory) 방법을 함께 사용하고 있음
- RNN 방식의 장점은 입력 값과 출력 값을 어떻게 설정하느냐에 따라 아래와 같이 3가지로 나눌수 있다.
-
- 다수 입력 단일 출력
-
- 단일 입력 다수 출력
-
- 다수 입력 다수 출력
-
SIMPLE RNN 실행
In [4]:
import tensorflow as tf
from tensorflow.keras.layers import SimpleRNN, LSTM, Bidirectional
tf.random.set_seed(1)
rnn_layer = tf.keras.layers.SimpleRNN(units=2, use_bias = True, return_sequences = True )
rnn_layer.build(input_shape=(None, None, 5))
w_xh, w_oo, b_h = rnn_layer.weights
print("w_xhm의 크기:", w_xh)
print("w_00의 크기:", w_oo)
print("b_h의 크기:", b_h)
w_xhm의 크기: <tf.Variable 'simple_rnn_cell_1/kernel:0' shape=(5, 2) dtype=float32, numpy=
array([[-0.6200572 , 0.7433989 ],
[ 0.242517 , -0.12119704],
[-0.38525409, 0.2638626 ],
[ 0.8809836 , -0.12017238],
[ 0.2964511 , 0.19422936]], dtype=float32)>
w_00의 크기: <tf.Variable 'simple_rnn_cell_1/recurrent_kernel:0' shape=(2, 2) dtype=float32, numpy=
array([[ 0.98796964, 0.15464693],
[-0.15464693, 0.9879698 ]], dtype=float32)>
b_h의 크기: <tf.Variable 'simple_rnn_cell_1/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>
LSTM을 이용한 로이터 뉴스 카테고리 분류하기
- Embedding 층은 데이터 전처리 과정을 통해 입력된 값을 받아 다음 층이 알아들을 수 있는 형태로 변환하는 역할을 함
- ->Embedding('불러온 단어의 총 개수', '기사당 단어 수') 형식으로 사용하며, 모델 설정 부분의 맨 처음에 있어야 함
- LSTM은 앞서 설명했듯이 RNN에서 기억 값에 대한 가중치를 제어함
- LSTM(기사당 단어 수, 기타 옵션)의 형태로 적용됨
- LSTM의 활성화 함수로는 Tanh를 사용
In [19]:
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.preprocessing import sequence
from keras.utils import np_utils
import numpy
import tensorflow as tf
import matplotlib.pyplot as plt
# seed 값 설정
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
# 불러온 데이터를 학습셋과 테스트셋으로 나누기
# num_words는 빈도가 1~ 1000에 해당하는 단어만 선택해서 불러오는 것이다.
(X_train, Y_train), (X_test, Y_test) = reuters.load_data(num_words=1000, test_split=0.2)
from keras.preprocessing import sequence
# 데이터 전처리
x_train = sequence.pad_sequences(X_train, maxlen =100)
x_test = sequence.pad_sequences(X_test, maxlen = 100)
y_train = np_utils.to_categorical(Y_train)
y_test = np_utils.to_categorical(Y_test)
# 모델의 설정
model = Sequential()
model.add(Embedding(1000,100))
model.add(LSTM(100, activation = 'tanh'))
model.add(Dense(46, activation = "softmax"))
# 모델의 컴파일
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델의 실행
history = model.fit(x_train, y_train, batch_size=100, epochs=20, validation_data=(x_test,
y_test))
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test) [1]))
Epoch 1/20
90/90 [==============================] - 25s 261ms/step - loss: 2.5634 - accuracy: 0.3656 - val_loss: 2.1688 - val_accuracy: 0.4889
Epoch 2/20
90/90 [==============================] - 23s 260ms/step - loss: 2.0425 - accuracy: 0.4951 - val_loss: 2.0114 - val_accuracy: 0.5107
Epoch 3/20
90/90 [==============================] - 24s 261ms/step - loss: 1.9406 - accuracy: 0.5197 - val_loss: 2.0824 - val_accuracy: 0.5102
Epoch 4/20
90/90 [==============================] - 24s 264ms/step - loss: 1.7750 - accuracy: 0.5596 - val_loss: 1.8240 - val_accuracy: 0.5378
Epoch 5/20
90/90 [==============================] - 23s 261ms/step - loss: 1.6615 - accuracy: 0.5780 - val_loss: 1.6379 - val_accuracy: 0.5899
Epoch 6/20
90/90 [==============================] - 21s 238ms/step - loss: 1.5712 - accuracy: 0.5996 - val_loss: 1.6547 - val_accuracy: 0.5935
Epoch 7/20
90/90 [==============================] - 21s 232ms/step - loss: 1.5026 - accuracy: 0.6196 - val_loss: 1.5135 - val_accuracy: 0.6220
Epoch 8/20
90/90 [==============================] - 20s 227ms/step - loss: 1.3963 - accuracy: 0.6463 - val_loss: 1.4651 - val_accuracy: 0.6354
Epoch 9/20
90/90 [==============================] - 21s 235ms/step - loss: 1.3232 - accuracy: 0.6668 - val_loss: 1.4081 - val_accuracy: 0.6349
Epoch 10/20
90/90 [==============================] - 20s 227ms/step - loss: 1.2889 - accuracy: 0.6737 - val_loss: 1.3881 - val_accuracy: 0.6438
Epoch 11/20
90/90 [==============================] - 21s 231ms/step - loss: 1.2133 - accuracy: 0.6908 - val_loss: 1.3212 - val_accuracy: 0.6572
Epoch 12/20
90/90 [==============================] - 21s 229ms/step - loss: 1.1740 - accuracy: 0.6956 - val_loss: 1.3013 - val_accuracy: 0.6549
Epoch 13/20
90/90 [==============================] - 21s 233ms/step - loss: 1.1084 - accuracy: 0.7144 - val_loss: 1.2706 - val_accuracy: 0.6714
Epoch 14/20
90/90 [==============================] - 21s 230ms/step - loss: 1.0622 - accuracy: 0.7243 - val_loss: 1.2372 - val_accuracy: 0.6830
Epoch 15/20
90/90 [==============================] - 22s 245ms/step - loss: 0.9967 - accuracy: 0.7472 - val_loss: 1.2378 - val_accuracy: 0.6897
Epoch 16/20
90/90 [==============================] - 21s 231ms/step - loss: 0.9554 - accuracy: 0.7566 - val_loss: 1.2011 - val_accuracy: 0.6932
Epoch 17/20
90/90 [==============================] - 20s 227ms/step - loss: 0.9124 - accuracy: 0.7682 - val_loss: 1.1929 - val_accuracy: 0.7021
Epoch 18/20
90/90 [==============================] - 21s 233ms/step - loss: 0.8764 - accuracy: 0.7772 - val_loss: 1.2118 - val_accuracy: 0.6986
Epoch 19/20
90/90 [==============================] - 23s 255ms/step - loss: 0.8334 - accuracy: 0.7885 - val_loss: 1.1968 - val_accuracy: 0.7115
Epoch 20/20
90/90 [==============================] - 25s 279ms/step - loss: 0.8155 - accuracy: 0.7917 - val_loss: 1.1773 - val_accuracy: 0.7159
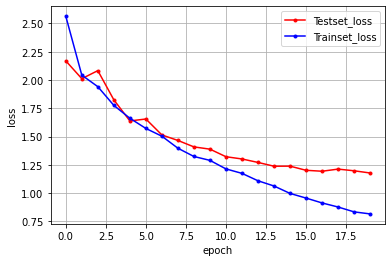
import matplotlib.pyplot as plt
import numpy
# 테스트셋의 오차# 테스트셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 그래프로 표현
x_len = numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
728x90
'딥러닝' 카테고리의 다른 글
| 추천 시스템 (0) | 2022.05.16 |
|---|---|
| CNN - mnist 데이터 셋 (0) | 2022.05.11 |
| 퍼셉트론 (0) | 2022.04.29 |
| 딥러닝 기초 (0) | 2022.04.29 |