분류(Classification)는 학습 데이터로 주어진 데이터의 피처와 레이블값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측 하는 것이다.
대표적인 분류 알고리즘
1. 베이즈 통계와 생성 모델에 기반한 나이브 베이즈
2. 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀
3. 데이터 균일도에 따른 규칙 기반의 결정트리
4. 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신
5. 근접 거리를 기준으로 하는 최소 근접 알고리즘
6. 심층 연결 기반의 신경망
7. 서로 다르거나 같은 머신러닝 알고리즘을 결합한 앙상블
결정 트리: 매우 쉽고 유연하게 적용 될 수 있는 알고리즘으로 데이터의 스케일링이나 정규화 등의 사전 가공의 영향이 매우 적다. 하지만 예측 성능을 향상시키기 위해 복잡한 규칙 구조를 가져야 하며 이로 인한 과적합이 발생해 반대로 예측 성능이 저하될 수도 있다.
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만든다. 이에 따라 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우한다.
앙상블: 매우 많은 여러개의 약한 학습기를 결합해 확률적 보완과 오류가 발생한 부분에 대한 가중치를 계속 업데이트하면서 예측 성능을 향상시킨다.(GBM, XGBoost, LightGBM)
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisioTree Classifier 생성
dt_clf = DecisionTreeClassifier(max_depth=3, random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
# DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)
Out[23]:
DecisionTreeClassifier(max_depth=3, random_state=156)In [24]:
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf,out_file="tree.dot", class_names=iris_data.target_names , feature_names=iris_data.feature_names, impurity=True, filled=True)
In [26]:
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook 상에서 시각화
with open("tree.dot") as f:
dot_graph=f.read()
graphviz.Source(dot_graph)
Out[26]:
petal length (cm) <= 2.45gini = 0.667samples = 120value = [41, 40, 39]class = setosagini = 0.0samples = 41value = [41, 0, 0]class = setosaTruepetal width (cm) <= 1.55gini = 0.5samples = 79value = [0, 40, 39]class = versicolorFalsepetal length (cm) <= 5.25gini = 0.051samples = 38value = [0, 37, 1]class = versicolorpetal width (cm) <= 1.75gini = 0.136samples = 41value = [0, 3, 38]class = virginicagini = 0.0samples = 37value = [0, 37, 0]class = versicolorgini = 0.0samples = 1value = [0, 0, 1]class = virginicagini = 0.5samples = 4value = [0, 2, 2]class = versicolorgini = 0.053samples = 37value = [0, 1, 36]class = virginica
결정 트리의 Feature 선택
In [27]:
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_,3)))
# featrue 별 importance 매핑
for name, value, in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
#feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_, y = iris_data.feature_names)
Feature importances:
[0. 0. 0.558 0.442]
sepal length (cm) : 0.000
sepal width (cm) : 0.000
petal length (cm) : 0.558
petal width (cm) : 0.442
Out[27]:
<AxesSubplot:>
Decision Tree의 과적합(Overfitting)
In [28]:
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
plt.title("3 Class values with 2 Features Sample Data Creation")
# 2차원 시각화를 위해 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2,
n_classes=3, n_clusters_per_class=1, random_state=0)
# 그래프 형태로 2개의 피쳐로 2차원 좌표 시각화, 각 클래스 값은 다른 색으로 표시
plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, edgecolor = 'k', cmap='rainbow')
Out[28]:
<matplotlib.collections.PathCollection at 0x2185940c550>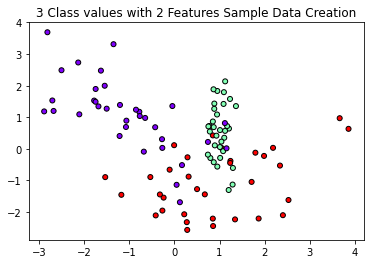
In [30]:
# Classifier의 Decision Boundary를 시각화 하는 함수
def visualize_boundary(model, X, y):
fig,ax = plt.subplots()
# 학습 데이타 scatter plot으로 나타내기
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k',
clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start , xlim_end = ax.get_xlim()
ylim_start , ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이타로 model 학습 .
model.fit(X, y)
# meshgrid 형태인 모든 좌표값으로 예측 수행.
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# contourf() 를 이용하여 class boundary 를 visualization 수행.
n_classes = len(np.unique(y))
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow', clim=(y.min(), y.max()),
zorder=1)
# 특정한 트리 생성에 제약이 없는(전체 default 값) Decision Tree의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier().fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
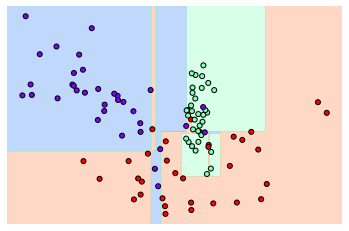
In [31]:
# min_samples_leaf = 6 으로 설정한 Decision Tree의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
728x90
'머신러닝' 카테고리의 다른 글
| 머신 러닝 -분류 학습(Ensemble Learning) (0) | 2022.04.13 |
|---|---|
| 타이타닉 생존자 분류 예측 (0) | 2022.04.13 |
| 성능평가 - ROC 곡선과 AUC (0) | 2022.04.12 |
| 성능평가- confusion Matrix (0) | 2022.04.12 |
| 붓꽃 데이터 사이킷 런 학습-GridSearchCV (0) | 2022.04.11 |